Deep Learning e s el término de moda últimamente. Parece que cualquier avance importante en aprendizaje automático se apoya en el famoso término. En el momento de escribir este artículo, no hay a penas recursos en español, por eso he decidido escribirlo en ese idioma. Con el objetivo de que sea lo más ameno posible, voy a evitar las fórmulas matemáticas. Encontrarás enlaces a artículos en inglés con las fórmulas en caso de que las necesites.
s el término de moda últimamente. Parece que cualquier avance importante en aprendizaje automático se apoya en el famoso término. En el momento de escribir este artículo, no hay a penas recursos en español, por eso he decidido escribirlo en ese idioma. Con el objetivo de que sea lo más ameno posible, voy a evitar las fórmulas matemáticas. Encontrarás enlaces a artículos en inglés con las fórmulas en caso de que las necesites.
Voy a comenzar el artículo presentando las redes de neuronas y su entrenamiento, y a continuación cómo se pueden utilizar para realizar Deep Learning. Si ya estás familiarizado con las redes de neuronas, puedes saltar directamente a la sección de auto-codificadores.
Redes de neuronas
Aunque existen varias maneras de implementar Deep Learning, una de las más comunes es utilizar redes de neuronas. Una red de neuronas es una herramienta matemática que modela, de forma muy simplificada, el funcionamiento de las neuronas en el cerebro. Dicho así suena bastante complicado, pero en realidad es una serie de operaciones matemáticas sobre una lista de números, que da como resultado otra lista de números. Otra forma de verlas, es como un procesador de información, que recibe información entrante, codificada como números, hace un poco de magia, y produce como resultado información saliente, codificada como otros números.
Un ejemplo concreto sería una red de neuronas que detecte rostros en imágenes. Es muy fácil codificar una imagen como una lista de números. De hecho, ya las codificamos así en los ordenadores. Por tanto, esta red recibiría tantos números a su entrada como píxeles tienen nuestras imágenes (o tres por cada píxel si utilizamos imágenes en color). Y si la información que esperamos a la salida es que nos diga si hay un rostro o no, basta con un solo número. en la lista saliente. Podemos imaginar que si ese número, que sale de la red, toma un valor cercano a 1.0 significa que hay un rostro, y si toma un valor cercano a 0.0 significa que no lo hay. Valores intermedios se pueden interpretar como inseguridad, o probabilidad.
Arquitectura
En el siguiente diagrama podemos ver la arquitectura de una red de neuronas. Cada círculo representa una neurona. Las neuronas se organizan en capas, de la siguiente forma: las neuronas amarillas son las entradas, y reciben cada uno de los números de nuestra lista de números entrante, las neuronas verdes son las salidas, y una vez que la red realiza su operación matemática, contienen el resultado, también como una lista de números; las neuronas grises son neuronas ocultas, que contienen cálculos intermedios de la red.

Arquitectura de una red de neuronas.
Normalmente todas las neuronas de cada capa tienen una conexión con cada neurona de la siguiente capa, como se representa en el diagrama. Estas conexiones tienen asociado un número, que se llama peso. La principal operación que realiza la red de neuronas consiste en multiplicar los valores de una neurona por los pesos de sus conexiones salientes. Cada neurona de la siguiente capa recibe números de varias conexiones entrantes, y lo primero que hace es sumarlos todos.
Continuando con el ejemplo anterior, la arquitectura de la red que detecta rostros en una imagen, tendría un aspecto similar al siguiente (sólo se dibujan las conexiones desde tres píxeles para no liar el gráfico):

Arquitectura de la red de neuronas para detectar elementos en una imagen.
Función de activación
Hasta el momento, la operación de la red de neuronas es sencilla, se trata de productos y sumas. Hay otra operación que realizan todas las capas salvo la capa de entrada, antes de continuar multiplicando sus valores por las conexiones salientes, se trata de la función de activación. Esta función recibe como entrada la suma de todos los números que llegan por las conexiones entrantes, transforma el valor mediante una fórmula, y produce un nuevo número. Existen varias opciones, pero una de las funciones más habituales es la función sigmoide. Uno de los objetivos de la función de activación es mantener los números producidos por cada neurona dentro de un rango razonable (por ejemplo, números reales entre 0 y 1).
La función sigmoide es no lineal, esto significa que si dibujamos en una gráfica los valores de entrada en un eje y los de salida en el otro eje, el dibujo no será una línea. Esto es muy importante, porque si la función de activación que elegimos es lineal, la red estará limitada a resolver problemas lineales (muy simples).
Un ejemplo de problema lineal sería la conversión de temperatura entre Celsius (Europa) y Fahrenheit (EEUU). Si dibujamos uno frente a otro en una gráfica, el resultado será una línea.

Transformación lineal (izquierda) frente a no lineal (derecha).
Un ejemplo de problema no lineal es la posición vertical de una manzana cayendo con respecto al tiempo. Si dibujamos la posición de la manzana en un eje, y el tiempo en otro, la gráfica será una curva, debido a la aceleración de la gravedad.
Implementación
Una forma sencilla de implementar redes de neuronas consiste en almacenar los pesos en matrices. Es fácil ver que si ahora guardamos los valores de todas las neuronas de una capa en un vector, el producto del vector y la matriz de pesos de salida, nos da los valores de entrada de cada neurona en la siguiente capa. Ahora sólo falta aplicar la función de activación que hayamos elegido a cada elemento de ese segundo vector, y repetir el proceso. Si disponemos de una biblioteca que implemente matrices, se puede implementar la red en unas pocas líneas.
Ya existen muchas librerías de código abierto que implementan redes de neuronas, como libfann.
Bias
Justo antes de aplicar la función de activación, cada neurona añade a la suma de productos un nuevo término constante, llamado habitualmente bias. Una forma típica de implementar este término consiste en imaginarse que extendemos la capa anterior con una falsa neurona que siempre toma como valor un 1.0, e incorporar los pesos correspondientes a dicha falsa neurona a la matriz de pesos.

Red de neuronas con bias (los valores de bias se representan como conexiones azules).
Para ver su importancia con un ejemplo muy sencillo, imaginémonos una función de activación lineal (no hacer nada), y sólo dos neuronas en la red (una en la capa de entrada, y otra en la capa de salida). Tal como hemos explicado antes, esta red se limita a hacer una multiplicación y nada más. Si queremos usar esta red para convertir entre Celsius y Fahrenheit, tenemos un problema, porque a 0ºC le corresponden 32ºF, y sólo con una multiplicación no podemos hacer esto. Sin embargo, al introducir el término Bias, tenemos una multiplicación y luego una suma, con lo cual ya podríamos hacer el conversor de ºC a ºF.
Otras arquitecturas
Sin entrar en detalles, es interesante saber que existen arquitecturas de redes de neuronas diferentes que también se usan en ocasiones para implementar Deep Learning.
Por ejemplo, las redes de neuronas recurrentes no tienen una estructura de capas, sino que permiten conexiones arbitrarias entre todas las neuronas, incluso creando ciclos. Esto permite incorporar a la red el concepto de temporalidad, y permite que la red tenga memoria, porque los números que introducimos en un momento dado en las neuronas de entrada, son transformados y continúan circulando por la red incluso después de cambiar los números de entrada por otros diferentes.
Otra arquitectura interesante son las redes de neuronas convolutivas (Convolutional neural networks). En este caso se mantiene el concepto de capas, pero cada neurona de una capa no recibe conexiones entrantes de todas las neuronas de la capa anterior, sino sólo de algunas. Esto favorece que una neurona se especialice en una región de la lista de números de la capa anterior, y reduce drásticamente el número de pesos y de multiplicaciones necesarias. Lo habitual es que dos neuronas consecutivas de una capa intermedia se especialicen en regiones solapadas de la capa anterior. Quienes conozcan el concepto de convolución, entenderán de dónde sale el nombre.
Aprendizaje en redes de neuronas
Supongamos que ya tenemos claro cuantas neuronas nos hacen falta a la entrada y a la salida, porque ya hemos decidido cómo representar nuestra información en forma de listas de números. Todavía nos faltan varias cosas por decidir para tener una red que funcione:
- Cuántas capas ocultas vamos a incluir.
- Cuántas neuronas vamos a poner en cada capa oculta.
- Qué pesos concretos usaremos en las conexiones entre cada par de capas.
Habitualmente los dos primeros puntos se deciden a mano, y algunas veces mediante prueba y error. Lógicamente, cuantas más neuronas tengamos en capas ocultas, más compleja es la red, y podrá resolver a su vez problemas más complejos. Por otra parte, cuantas más neuronas ocultas tengamos, más costará realizar todos los productos y sumas.
Es importante mencionar que si hemos elegido una función de activación lineal, no merece la pena utilizar capas ocultas en absoluto, porque se puede comprobar que la potencia de la red será la misma por muchas capas que pongamos. La potencia de la red sólo aumenta con el número de capas para funciones de activación no lineales, como la sigmoide.
El tercer punto, afortunadamente, se puede resolver de forma automática, mediante un proceso llamado entrenamiento. Para entrenar una red de neuronas, necesitamos primero recopilar algunos ejemplos de entradas y la salida que deseamos para cada ejemplo. Por ejemplo, en el detector de rostros, necesitamos recopilar ejemplos de imágenes con rostros, y ejemplos de imágenes sin rostros. También necesitamos etiquetar cuales son las imágenes que tienen rostros y cuales las que no, porque esa es precisamente la salida deseada para cada ejemplo. Este proceso de entrenamiento se conoce como aprendizaje supervisado, porque el sistema necesita de un supervisor que le explique lo que tiene que hacer (mediante ejemplos de entradas y salidas).
Propagación hacia atrás (backpropagation)
Una vez que tenemos un conjunto de ejemplos, es muy fácil evaluar la red con cada ejemplo y comprobar el error entre la salida deseada y la salida que está produciendo la red. Para calcular el error, en cada neurona de la capa de salida, restamos el valor producido y el que esperábamos que se produjese. Sabiendo cual es el error para un determinado ejemplo, podemos intentar corregirlo.
La idea para corregir errores consiste en buscar culpables. Entre las neuronas de salida es fácil saber quienes son las culpables: sabemos exactamente cuánto error se produce en cada neurona, tal como se explicó antes. Pero cada una de esas neuronas está conectada con las neuronas anteriores mediante unos pesos. Podemos usar esos pesos para determinar cuanto contribuyen las neuronas anteriores al error, simplemente propagando los errores hacia atrás del mismo modo que propagamos valores hacia delante, multiplicando y sumando. De este modo, podemos saber cuanto contribuye al error cada neurona de toda la red.
Sabiendo cuanto contribuye cada neurona al error, podemos intentar actualizar los pesos para reducir ese error. Primero necesitamos averiguar cómo afectan al error los cambios producidos a los pesos. Dicho de otra forma, necesitamos determinar la velocidad con que cambia el error con respecto a los pesos. Sabiendo esto, el siguiente paso consiste en cambiar los pesos en la medida justa para que el error se reduzca a la mayor velocidad posible.
La velocidad con que cambia el error con respecto a los pesos se calcula con derivadas parciales, e implica que debemos ser capaces de derivar la función de activación. No quiero entrar en detalles matemáticos, tenéis una explicación detallada en el artículo de wikipedia sobre propagación hacia atrás, por si queréis programar vuestra propia red de neuronas con aprendizaje. La biblioteca libfann mencionada anteriormente incluye este algoritmo e incluso algunas variaciones.
¿Y cómo empezamos el proceso? Pues con pesos generados al azar. Más adelante veremos alguna alternativa.
Al utilizar una librería de redes de neuronas existente, lo más habitual es que al entrenar obtengamos información de cómo va el proceso en forma de error cuadrático medio (MSE). La idea es que para cada ejemplo que tenemos, la red evalúa el error en todas sus neuronas de salida tal como indicamos antes, eleva cada uno de esos números al cuadrado, y finalmente calcula el promedio. Al elevar cada error al cuadrado, los errores siempre son positivos, así que los errores de unas neuronas no anulan a los de otras. Es importante recordar que no se trata de un porcentaje. Para decidir cual es el error mínimo a partir del cual podemos parar de entrenar, una forma sencilla es decidir el máximo error que estamos dispuestos aceptar para cada neurona de salida, calcular los cuadrados y luego la media.
Límites de la propagación hacia atrás
Un grave problema de los algoritmos de propagación hacia atrás es que el error se va diluyendo de forma exponencial a medida que atraviesa capas en su camino hasta el principio de la red. Esto es un problema porque en una red muy profunda (con muchas capas ocultas), sólo las últimas capas se entrenan, mientras que las primeras apenas sufren cambios. Por eso a veces compensa utilizar redes con pocas capas ocultas que contengan muchas neuronas, en lugar de redes con muchas capas ocultas que contengan pocas neuronas. Esto era así hasta que Deep Learning se puso de moda, como veremos más adelante.
Auto-codificadores (autoencoders)
Otra de las herramientas utilizadas habitualmente para implementar Deep Learning son los auto-codificadores (autoencoders). Normalmente se implementan como redes de neuronas con tres capas (sólo una capa oculta).
Un auto-codificador aprende a producir a la salida exactamente la misma información que recibe a la entrada. Por eso, las capas de entrada y salida siempre deben tener el mismo número de neuronas. Por ejemplo, si la capa de entrada recibe los píxeles de una imagen, esperamos que la red aprenda a producir en su capa de salida exactamente la misma imagen que le hemos introducido. A primera vista parece un artilugio bastante inútil, básicamente no hace nada.

Ejemplo de auto-codificador de imágenes. Cada caja representa una capa de neuronas.
La clave está en la capa oculta. Imaginémonos por un momento un auto-codificador que tiene menos neuronas en la capa oculta que en las capas de entrada y salida. Dado que exigimos a esta red que produzca a la salida el mismo resultado que recibe a la entrada, y la información tiene que pasar por la capa oculta, la red se verá obligada a encontrar una representación intermedia de la información en su capa oculta usando menos números. Por tanto, al aplicar unos valores de entrada, la capa oculta tendrá una versión comprimida de la información, pero además será una versión comprimida que se puede volver a descomprimir para recuperar la versión original a la salida.

Ejemplo de auto-codificador.
De hecho, una vez entrenada, se puede dividir la red en dos, una primera red que utiliza la capa oculta como capa de salida, y una segunda red que utiliza esa capa oculta como capa de entrada. La primera red sería un compresor, y la segunda un descompresor.
Precisamente por eso, este tipo de redes se denominan auto-codificadores, son capaces de descubrir por si mismos una forma alternativa de codificar la información en su capa oculta. Y lo mejor de todo es que no necesitan a un supervisor que les muestre ejemplos de cómo codificar información, se buscan la vida ellas solas. Por eso se suele decir que se trata de aprendizaje no supervisado.
Auto-codificadores dispersos
El ejemplo de red que comprime información es interesante, pero no es el uso más habitual de estas redes en Deep Learning. ¿Qué pasaría si la capa oculta, en lugar de tener menos neuronas, tuviese más que las capas de entrada y salida? Existe un riesgo, y es que la red no aprenda nada: que se limite a copiar la entrada a un subconjunto de las neuronas en la capa oculta (dejando las neuronas sobrantes sin usar), y luego las vuelva a copiar a la salida. Pero ¿y si pudiésemos forzar que las neuronas de la capa oculta se activen pocas veces? Entonces la red tendría que aprender nuevamente un código alternativo, y además, disperso.

Ejemplo de auto-codificador disperso.
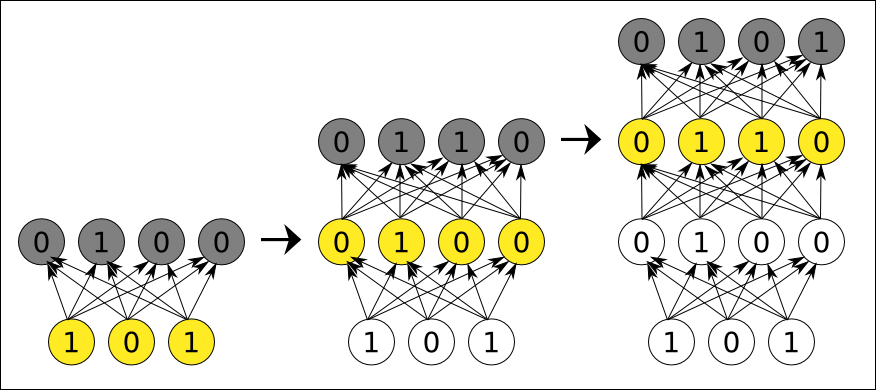
La idea del código disperso es que los valores en las neuronas de la capa oculta sean 0 la mayor parte de las veces. Para cada ejemplo, sólo unas pocas neuronas tendrían un valor alto, y las demás estarían cerca de 0. En la imagen anterior, el ejemplo de entrada [1, 0, 1] se representa en la capa oculta mediante los valores [0, 1, 0, 0]. Sólo una neurona se activa. Al introducir una restricción de dispersión, la capa oculta no puede representar tantas combinaciones de valores como podría representar si no tuviese esa restricción. Por ejemplo, nunca podrá tomar los valores [1, 1, 1, 1]. Esto limita mucho la expresividad de la capa oculta, pero a cambio obliga a que cada neurona de esa capa se especialice en un cierto patrón en la entrada.
Hay varias formas de conseguir que la red no se limite a copiar la información sin más cuando la capa oculta tiene neuronas de sobra (se pueden incluso combinar):
- Añadir, a la hora de calcular el error, un factor de dispersión. Si la dispersión es baja, añadiría mucho error, y si es alta, poco error. No es muy complicado de hacer, simplemente debemos buscar una fórmula que podamos diferenciar, para poder actualizar los pesos. Muchas bibliotecas de redes de neuronas no tienen esta funcionalidad, así que necesitaríamos implementar la nuestra. La mayor dificultad radica en encontrar el factor de dispersión adecuado para nuestro problema, ya que diferentes factores cambian significativamente el rendimiento del auto-codificador.
- Al componer los ejemplos, en lugar de indicar el mismo valor para las entradas y las salidas, introducir un poco de ruido en el vector de entrada, y dejar el de salida sin ruido. De esta forma, la red está forzada a generalizar, porque tendrá varios ejemplos ligeramente diferentes de entrada que producen la misma salida. La representación intermedia en la capa oculta tendrá que enfocarse en las características comunes de todas las versiones de la misma imagen con diferentes ruidos. Una ventaja de este método es que multiplicamos los ejemplos que tenemos, porque podemos usar el mismo ejemplo varias veces con distintos ruidos. Además podemos usar cualquier biblioteca de redes de neuronas ya existente.
En ambos casos la red está forzada a generalizar, y encontrar patrones en los ejemplos que pueda representar mediante las neuronas de su capa oculta. Estos patrones son características frecuentes en los ejemplos. De hecho, es muy sencillo descubrir cual es la información de entrada que provoca una activación total en una de las neuronas de la capa oculta, o lo que es lo mismo, qué característica representa cada una de estas neuronas: basta con resolver una ecuación.
Para ver un ejemplo concreto, imaginémonos que utilizamos las imágenes de dígitos escritos a mano de la base de datos MNIST. Esta base de datos contiene dígitos como los mostrados a continuación:

Ejemplo de dígitos escritos a mano.
Para entrenar un auto-codificador, supongamos que recortamos parches de 8×8 píxeles de esta base de datos, y configuremos el auto-codificador con 100 neuronas en su capa oculta. Tal como se explicó, mostraremos a la red el mismo parche a la entrada y la salida, y la red aprenderá una codificación intermedia. Ahora, si dibujamos el parche que activa completamente cada una de las 100 neuronas de la capa oculta, obtendremos el siguiente gráfico (los 100 patrones se han distribuido en una matriz 10×10 por comodidad):

Patrones que activan cada una de las 100 neuronas de un auto-codificador.
Como se puede apreciar en la imagen, los parches que activan al máximo cada neurona de la capa oculta representan características fundamentales de los dígitos, como esquinas, líneas con distintos ángulos, algunas curvas, e incluso algunos círculos (probablemente para los ochos).
Para entrenar el auto-codificador se utilizó solamente la técnica de añadir ruido en la entrada, concretamente píxeles negros con una probabilidad del 20%.
Como os podéis imaginar, una vez entrenado un auto-codificador, la segunda mitad de la red se puede descartar, normalmente nos interesa sólo la parte que codifica.
Apilando auto-codificadores
Un solo auto-codificador puede encontrar características fundamentales en la información de entrada, las características más primitivas y simples que se pueden extraer de esa información, como rectas y curvas en el caso de las imágenes. Sin embargo, si queremos que nuestras máquinas detecten conceptos más complejos como rostros, nos hace falta más potencia.
Fijémonos en la operación que realiza un auto-codificador en su capa oculta. A partir de información cruda sin significado (por ejemplo, píxeles de imágenes), es capaz de etiquetar características algo más complejas (por ejemplo, formas simples presentes en cualquier imagen como líneas y curvas). Entonces la pregunta es, ¿qué pasa si al resultado codificado, en esa capa oculta, le aplicamos otro auto-codificador? Si lo hacemos bien, encontrará características más complejas todavía (como círculos, arcos, ángulos rectos, etc). Si continuamos haciendo esto varias veces, tendremos una jerarquía de características cada vez más complejas, junto con una pila de codificadores. Siguiendo el ejemplo de las imágenes, dada una profundidad suficiente e imágenes de ejemplo suficientes, conseguiremos alguna neurona que se active cuando la imagen tenga un rostro, y sin necesidad de que ningún supervisor le explique a la red cómo es un rostro.
La idea de Deep Learning mediante auto-codificadores apilados es precisamente esa, usar varios codificadores, y entrenarlos uno a uno, usando cada codificador entrenado para entrenar el siguiente. Podríamos llamarlo un algoritmo voraz (greedy), y éste es realmente el gran avance del Deep Learning que permite hacer todas esas cosas tan fantásticas que leemos últimamente.
Auto codificadores apilados.
Una red profunda creada de este modo tiene dos características muy importantes:
- Aprende sin supervisión, sólo necesita datos y encuentra ella sola características frecuentes con las que etiquetar los datos.
- Podemos entrenar redes todo lo profundas que queramos. Tal como se comentó en la sección de propagación hacia atrás, al entrenar redes muy profundas teníamos un problema porque el error se va diluyendo y las primeras capas casi no se entrenan. Aquí no tenemos ese problema.
Incluso existen teorías sobre el desarrollo del cerebro humano que plantean la posibilidad de que también tenga aprendizaje secuencial por capas.
Convolución y pooling
En el ejemplo anterior sobre los dígitos escritos a mano, usamos parches de imagen de 8×8 píxeles para entrenar un auto-codificador. La pregunta es, ¿por qué no introducir las imágenes completas?
- Cuanto mayor es la entrada del auto-codificador, más pesos hay que entrenar, y más lento es todo el proceso de entrenamiento. Si tenemos imágenes de 1000×1000 pixeles, y utilizamos 1000 neuronas en la capa oculta, necesitaríamos entrenar 2000 millones de pesos, mientras que si utilizamos parches de 8×8 y utilizamos 100 neuronas en la capa oculta, entrenamos sólo 12800 pesos.
- Si usamos imágenes enteras, para el auto-codificador una imagen que tenga un rostro centrado, y otra que tenga el mismo rostro ligeramente desplazado hacia un lado, son completamente diferentes.
Especialmente con el fin de resolver el segundo punto, se puede utilizar una técnica conocida como convolución, y que está basada en cómo se estructuran realmente las neuronas en nuestro sistema visual.
La idea de base es, ¿qué más da dónde aparezca un círculo? Un círculo sigue siendo un círculo aunque lo desplacemos.
Por eso, podemos entrenar un auto-codificador con parches de imagen, y luego desplazar el codificador por toda la imagen, como si fuese un escáner, buscando características. Este proceso transforma la matriz de píxeles en otra matriz de características (listas de números) producidas por el codificador. Es esencialmente la misma imagen, pero cada pixel es mucho más rico en información, y contiene información de la región en que se encuentra el pixel, no sólo del pixel aislado.

Ejemplo de convolución con una ventana de 2×2.
El siguiente paso, llamado pooling, consiste en agrupar las características (listas de números) de varias coordinadas contiguas de la imagen, con alguna función de agrupación (la media, o el máximo). Esta etapa reduce la resolución de la imagen. A continuación podemos continuar haciendo convolución y pooling hasta que nos quede una imagen de 1×1 pixeles con muchísima información, o podemos incluir auto-codificadores intermedios que procesen los datos para buscar características de más alto nivel.

Ejemplo de pooling con una ventana de 2×2 y calculando el promedio.
En una sola etapa de convolución y pooling, obtenemos una imagen de menos resolución, y que en cada píxel nos cuenta la siguiente historia: «en esta región de la imagen hay un círculo y una línea». No nos dice exactamente dónde estaba el círculo en la matriz con la resolución original. Si ahora acoplamos otro auto-codificador, alguna neurona puede aprender a activarse siempre que reciba esta información agregada acerca de un círculo y una línea, y cuando apliquemos todo el sistema a nuestros números, esa neurona se activará cuando la imagen tenga dibujado el número nueve, por ejemplo.
Aprendizaje supervisado y Deep Learning
¿Qué pasa si realmente necesitamos realizar aprendizaje supervisado? Por ejemplo, quizás no nos vale con que la red vea vídeos de YouTube y descubra por si sola el concepto de gato, sino que queremos que aprenda a etiquetar objetos concretos que nos interesan.
Dado que todos esos codificadores compuestos son una red de neuronas convencional, podemos continuar con un entrenamiento supervisado convencional (propagación hacia atrás).
Al usar propagación hacia atrás, volvemos al problema del error que se diluye y, por tanto, las primeras capas van a sufrir un menor entrenamiento que las últimas. Pero precisamente las primeras capas son las que menos cambios necesitan, porque se enfocan en características fundamentales (de muy bajo nivel) necesarias para detectar cualquier objeto complejo. Cuanto más cerca está una capa de la salida, más nos interesa que sufra cambios en el entrenamiento supervisado y se enfoque en detectar los objetos complejos que a nosotros nos interesan.
Por eso, una técnica muy habitual en Deep Learning consiste en entrenar de manera no supervisada una pila de auto-codificadores, y a continuación, componer los codificadores y continuar con un entrenamiento supervisado. Es decir, el entrenamiento supervisado, en lugar de empezar con pesos al azar, empieza con pesos útiles, especialmente para las primeras capas.
Habitualmente es mucho más fácil encontrar información sin etiquetar (para la cual no tenemos una «salida deseada») que información etiquetada. Y de repente, toda esa información sin etiquetar resulta útil para la fase de entrenamiento no supervisado. En el ejemplo de los rostros en imágenes, podríamos usar todas las imágenes que encontremos por Internet para entrenar la pila de auto-codificadores, y luego unas pocas que manualmente hayamos etiquetado para refinar y que la red se fije simplemente en si hay o no rostros.
Alternativas
Los auto-codificadores no son el único mecanismo para realizar Deep Learning. Existen otras alternativas, como las Deep Belief Networks. Estas consisten también en una serie de capas entrenadas una a una, de la más específica a la más genérica, pero cada capa en lugar de un auto-codificador, utiliza una Restricted Boltzmann Machine. La idea general es la misma, sólo cambian algunos ladrillos.
Referencias
Deep learning se basa fundamentalmente en un montón de técnicas que ya existían con anterioridad. Algunas de estas técnicas son algo complejas, como el entrenamiento en redes de neuronas, pero existen un montón bibliotecas para múltiples lenguajes de programación que las implementan por vosotros. El gran avance ha sido la manera de combinarlas, especialmente el uso de auto-codificadores apilados que se entrenan capa a capa para lograr aprendizaje no supervisado eficiente.
A continuación os dejo una serie de referencias útiles si queréis implementar todas estas técnicas:
- Propagación hacia atrás (estándar).
- El algoritmo RPROP, una versión rapidísima del algoritmo de propagación hacia atrás. Muy recomendable si implementáis vuestra propia red de neuronas.
- FANN, una biblioteca de redes de neuronas que implementa tanto la propagación hacia atrás estándar como RPROP.
- Cómo visualizar un auto-encoder entrenado, con la fórmula que debemos aplicar, y un ejemplo de visualización.
- Técnicas para visualizar redes convolucionales, con ideas para reconstruir nuestra imagen original tras pasarla por una etapa de convolución+pooling.
- Tutorial sobre Deep Learning en inglés.
- Restricted Boltzmann Machines: Todas las fórmulas matemáticas que necesitáis para implementar esta alternativa a los auto-codificadores.
- Base de datos MNIST, con 60000 imágenes de dígitos escritos a mano, y las etiquetas indicando el dígito al que corresponde cada imagen.
- Base de datos CIFAR-10, con 60000 imágenes de objetos en color, clasificadas en 10 tipos diferentes de objeto.
- deeplearning.net, un portal en inglés con infinidad de recursos sobre deep learning.
Gracias a Silvia Izquierdo y Alberto Jaspe por revisar este artículo.
Actualización: Si te interesa la Inteligencia Artificial, no te pierdas el nuevo artículo sobre Q-learning!


Tremendo artículo! Aunque quizá mi opinión esté un poco sesgada por ser un tema que siempre me interesó, jeje
Gracias! Hiciste algún experimento con deep learning?
Hola Ruben que tal una pregunta lo que pasa es que me doy cuenta de que casi todos usan MNIST son 4 archivos raros por asi decirlo el cual los meten a variables que regrean un arreglo numpy.Pero yo tengo una gran variedad de imagenes en formato png.Me doy cuenta de que cuando abren el archivo Mnist les regresa un arreglo numpy.¿Con todas las imagenes que tengo como puedo hacer lo mismo pero con mis archivos de imagenes?
Muy buen articulo amigo, espero sigas escribiendo sobre este tema.
Gracias Jorge! No lo dudes, sigo aprendiendo y escribiré nuevos artículos cuando tenga suficiente material.
Fantástico artículo, ahora me toca profundizar con los enlaces relacionados.
Muchas gracias por la información.
Gracias! No dudes en avisar si encuentras otros enlaces útiles para aprender más sobre el tema.
Hola amigo..soy un estudiante y quisiera contactarle para hacerle un consulta por privado sobre sistemas expertos
le dejo mi correo usher-252@hotmail.com
Hola antony,
Por desgracia no le puedo ayudar con sistemas expertos, no he vuelto a usarlos desde que terminé mis estudios hace muchos años, y prácticamente he olvidado todo. Si profundiza sobre el tema y escribe algún artículo, no dude en compartir el enlace por aquí, estaré muy interesado en leerlo y refrescar ese tema!
Gracias!
Gracias por la respuesta amigo. no sabe de alguien que me pueda ayudar ?? alguien que sepa programa sistemas expertos ?? vera me dejaron un trabajo y necesito que alguien me lo haga yo se lo pagare.
Bueno en si es un proyecto que incluye sistemas expertos redes neuronales e IA
necesito ayuda amigo.
Pingback: Repaso didáctico sobre machine learning | La Pastilla Roja
Increíble el tema y tu aportación de lo mejor 🙂
Muchas gracias Ariadna, me alegro de que te haya resultado interesante!
Pingback: Q-learning: Aprendizaje automático por refuerzo | Rubén López
Un resumen muy claro. Gracias.
Gracias a ti!
Por cierto, si te interesa la inteligencia artificial en general, acabo de publicar otro artículo sobre aprendizaje por refuerzo: https://rubenlopezg.wordpress.com/2015/05/12/q-learning-aprendizaje-automatico-por-refuerzo/
Me tope de casualidad con su articulo, EXCELENTE por cierto!! Es muy dificil, teniendo conocimieno, tratar un tema tan profundo y actual de manera tan simple, clara y exacta. El caso es que estoy trabajando en el etiquetado de imagenes mediante Campos Aleatorios de Markov (MRF) + DeepLearning y me parece que probare primero este enfoque mas «simple» (si cabe la palabra) con redes neuronales convolutivas. Asi que gracias por la inspiracion. Saludos
Gracias David!
Échale un vistazo a este artículo: http://arxiv.org/abs/1411.4555
Usan redes convolutivas para extraer características de imágenes y luego LSTMs para generar leyendas.
Mucha suerte!
Hola Ruben. Tu artículo me ha parecido muy interesante. Estoy adentrandome en el mundo del deep learning y la lógica difusa (Sistemas Neuro-Difusos). Para resolver una problemática de mi tesis.
Te escribo por que en el rubro de «Redes Neuronales» menciones en la primera linea que «Existen varias implementaciones de Deep Learning además de las redes neuronales» me gustaría, si fueras tan amable de que me des una pista de que otras formas se puede implementar. Simplemente investigando todos hablan de redes neuronales. No encuentro otra alternativa de implementación. Espero tu respuesta muchas gracias!
Hola Felipe,
Bajo mi punto de vista, la principal alternativa a las redes neuronales para deep learning son las RBM (Restricted Boltzmann Machines). En la Wikipedia las describen como redes neuronales, pero no funcionan para nada como una red neuronal clásica. Ni la evaluación ni el entrenamiento se realizan por mecanismos tradicionales de redes de neuronas.
Otra alternativa más alejada de las redes de neuronas son las MKM (Multilayer Kernel Machine). Tienes el artículo de investigación donde lo introducen en este link: http://cseweb.ucsd.edu/~yoc002/paper/thesis_youngmincho.pdf.
Excelente artículo y enhorabuena Rubén, he buscado muchos articulos sobre el tema, incluso llegue a desempolvar mis apuntes de la universidad sobre inteligencia artificial, sistemas expertos… Has hecho que algo complejo sea comprensible para los demás.
Estoy empezando a trabajar en el análisis de patrones y comportamiento (ej. detección de fraudes) que requieren de un tratamiento ingente de datos y un tiempo de respuesta rapido y me parece que las redes neuronales son una excelente herramienta, ¿Nos podrias recomendar alguna herramienta didactica y sencilla para evaluar y construir nuestros propios modelos de indentificación de patrones usando «Deep Learning»?
Hola Sylvia,
Gracias por tus palabras! Te listo algunas herramientas que se están utilizando en este momento para trabajar con deep learning:
Theano con Pylearn: Es la herramienta más utilizada en este momento en la comunidad científica. Se programa en python, y permite utilizar CPU y GPU. Más detalles aquí: http://deeplearning.net/software/pylearn2/
Torch: El principal competidor de Theano. Están siempre intentando ganar al otro en rendimiento. Se programa en Lua, y soporta CPU y GPU también. Más detalles aquí: http://torch.ch/
Caffe: Es una herramienta enfocada casi exclusivamente al procesado de imágenes. Se programa en C++, y tamibén soporta CPU y GPU. Más info aquí: http://caffe.berkeleyvision.org/
Un par de puntos a tener en cuenta:
– Para trabajar con grandes volúmenes de datos, es mejor utilizar GPUs potentes que CPUs, principalmente por el ancho de banda de las GPU. Al trabajar con grandes volúmenes de datos, el principal cuello de botella es el ancho de banda.
– Si una GPU tarda demasiado en entrenar, es posible que necesites usar varias GPU en una sóla máquina (ej: SLI), o un cluster.
Si al final necesitas un cluster, echa un vistazo a Apache Hama: http://hama.apache.org/
Simplemente por completar con las últimas novedades, Google acaba de liberar http://www.tensorflow.org, que me parece una librería muy flexible que soporta no sólo deep learning, sino machine learning en general.
Puedes probar OpenNN, una librería muy popular en código abierto que implementa redes neuronales profundas.
Una herramienta profesional de deep learning con interfaz de usuario es Neural Designer.
Hola Ruben muy buen articulo y muy bien explicado, yo estoy haciendo reconocimiento de objetos y tengo imágenes de esos objetos.Tengo que añadir esta red neuronal por que no me los detecta muy bien me salen falses detecciones utilizo SVM y el algoritmo non-maximal-suppression,lo primero que hago es preprocesar las imágenes y luego extraer sus caracteristicas entrenar el modelo y hacer un SVM y por ultimo non-maximal supresssion pero como hay falsas detecciones necesito agreagr esta red neuronal sin embargo me encuentro con que las imagenes estan en 4 archivos en MNIST y este mismo te regresa un arreglo numpy.No se si tengas por ahi una alternativa para yo poder meter mis imagenes en lugar de MNIST tengo como 10000 imagenes en carpeta.
Hola Rafael,
Lo más cómodo seguramente sea usar la librería de python scipy, que tiene funciones para cargar imágenes y te devuelve vectores numpy. Por ejemplo:
scipy.misc.imread()
Aquí tienes un enlace directo a la documentación:
http://docs.scipy.org/doc/scipy-0.16.0/reference/generated/scipy.misc.imread.html
Suerte!
O no se si se pueda convertir mis 10000 imagenes en esos archivos MNIST pero no se como.
Enhorabuena por el articulo Rubén. He estado unas semanas leyendo sobre este tema, y es el artículo del que más he aprendido.
Mi objetivo es hacer un clasificador para reconocer en una carrera de coches quién es cada uno, deberá ser rápido porque lo quiero hacer sobre el propio vídeo.
Tengo demasiadas dudas acerca del tema y no encuentro por ningún lado nada que me guíe.
Los coches son todos iguales en forma así que la primera pregunta que tengo es ¿ hago un clasificador para que me reconozca la región en la que se encuentra un coche sea el que sea y luego recuperar esa región y aplicarle otro para que me reconozca cuál se encuentra dentro de esa región o debo de hacer un clasificador único?
La región en la que se encuentra un coche es importante porque se da el caso en que en una misma imagen puedan haber diferentes coches. He visto por ahí clasificadores de imágenes (con redes de neuronas) pero ninguna me deja claro cómo localizar el objeto dentro de la imagen. La pregunta es si ¿esto se puede hacer directamente con la red de neuronas?.
Y por último tengo varias imágenes de entrenamiento, estoy casi seguro que debo escalarlas para entrenar la red, lo que no se es como influirá cuando la red este reconociendo o que debería de hacer al reconocer. (Me baso bastante en la información que tengo sobre clasificadores Haar).
Gracias.
Gracias por tu comentario Victor!
Respecto al problema que planteas, si usas redes neuronales convolucionales, la posición y la escala de los objetos no son muy importantes para que la red aprenda, aunque vas a necesitar una gran cantidad de imágenes para el entrenamiento. Te dejo un artículo reciente que te puede resultar útil, donde usan redes de neuronas para reconocer objetos en imágenes en distintas posiciones y con diferentes escalas, que es muy parecido a lo que quieres hacer:
Haz clic para acceder a 1311.2524.pdf
Seguramente tu caso es más sencillo que lo que plantean en ese artículo, porque no buscas «cualquier objeto», sólo coches, pero a lo mejor puedes reutilizar algunas de sus ideas.
Una vez entrenado, si quieres que sea muy rápido para poder procesar 25/30 fps, vas a necesitar correr los modelos en una GPU potente (tipo Titan X), porque las redes profundas necesitan un montón de potencia de cálculo y, sobre todo, ancho de banda para leer millones de parámetros.
Suerte, ya contarás qué tal!
Muchas gracias, Ruben.
Esta muy bien el articulo que me has pasado, aunque espero que para mi problema pueda hacer una red de neuronas más pequeña para que no necesite tanta cantidad de procesamiento. Voy a leer un poco más sobre ellos a ver si es posible y si lo fuese ya comentaré a ver si puedo aportar algo.
Un saludo
Muy bueno tú artículo Rubén, yo estoy haciendo la tesis en verificación e identificación de rostros con deep learning y tu artículo me ha servido mucho para entender varias cosas que por haber tenido que leerlas en inglés no me habían quedado del todo claras.
Quisiera aprovechar la oportunidad para que si pudieras me aclararas una cosa: Las Redes Convolucionales para su entrenamiento usan varios rostros etiquetados, y la salida lo que tiene es el nivel de pertenencia de la entrada a cada clase usada para el entrenamiento, Y aquí viene mi pregunta: La capa anterior a la salida lo que tiene es una representación de la imagen, que se pudiera extraer y utilizar meramente como una representación de la imagen????
Muchas Gracias!!!!!!!!!
Gracias por tu comentario! Me alegro de que te haya resultado útil.
Todas las capas de una red de neuronas aplican una transformación a los datos de entrada, y por tanto contienen una representación de la imagen. Si utilizas entrenamiento supervisado para etiquetar, tal como comentas, cerca de la capa de salida los vectores contendrán representaciones útiles para clasificar las imágenes. Por ejemplo, dos imágenes muy diferentes, en la capa anterior a la salida podrían tener prácticamente la misma representación si pertenecen a la misma clase (si tienen la misma etiqueta).
Por poner un ejemplo, si entrenas tu red para identificar rostros, la red puede descartar toda la información de la imagen que no tenga que ver con rostros, como los fondos, los cuerpos, la ropa, etc. Las representaciones intermedias no necesitan codificar toda esa información, porque no es importante, y la red tenderá a usar toda su expresividad para representar características de rostros, porque son más útiles para el problema que estás resolviendo.
Si quieres que las representaciones no tengan tanta tendencia hacia un etiquetado concreto, y conseguir representaciones más genéricas, necesitas usar entrenamiento no supervisado, con la idea de los autoencoders apilados, por ejemplo. Cuando la red tiene que conseguir reconstruir la entrada lo mejor posible, no puede descartar ninguna información, y tendrá que encontrar formas de representar la imagen que preserven todo el detalle.
Como ves, dependiendo de lo que busques en esas representaciones, te puede interesar un entrenamiento supervisado, o uno no supervisado.
Espero que te resulte útil!
Muy buen artículo Rubén.
Enhorabuena!
Yo estoy haciendo una implementación en python con Theano para hacer análisis de sentimiento como proyecto final de máster…
Ya os contaré 😉
Gracias Christian!
Si vas a procesar texto, echa un vistazo al programa word2vec:
http://google-opensource.blogspot.ch/2013/08/learning-meaning-behind-words.html
Básicamente es capaz de codificar el significado de las palabras en vectores, de forma que palabras relacionadas tienen vectores relacionados, sinónimos tienen vectores muy próximos, etc. La gran ventaja es que no importa si en tu conjunto de entrenamiento nunca aparece, por ejemplo, la palabra «hogar», como word2vec va a generar un vector muy parecido a «casa», tu red seguramente va a hacer lo correcto igualmente.
Además word2vec aprende con texto sin etiquetar, con lo que te da una buena base para luego analizar sentimiento, que necesita texto etiquetado (más escaso).
Suerte con el proyecto! Cuando esté publicado en la web, pásanos el enlace.
Hola Ruben que técnica de deep learning me recomiendas para obtener a la salida una clasificación numérica debido a una serie de datos numéricos en la entrada. No trabajaré con imágenes solo valores numéricos Te agradeceria tu ayuda por favor
Hola Jesús,
Pues depende mucho de la naturaleza de esos valores numéricos. Por ejemplo, si es siempre un conjunto de números de tamaño fijo (por ejemplo, siempre 25 valores) puedes utilizar una red de neuronas normal, un perceptron multicapa.
Si la lista de valores es variable, tienes dos casos:
1. Si se trata de una secuencia, y hay correlaciones entre unos valores y los siguientes, entonces te compensa usar una red recurrente (busca LSTM).
2. Si no es una secuencia, y se trata de que no siempre tienes todos los valores, prueba un perceptron con todas las entradas posibles, y busca una codificación muy clara para la ausencia de valor, para que la red no confunda tener un valor a 0 con no tenerlo.
Piensa también en la función de activación para la salida. Si lo que vas a hacer es clasificar, y tienes N clases, lo mejor es utilizar softmax, que básicamente te da a la salida la probabilidad de que el patrón de entrada pertenezca a cada una de las N clases.
Otro consejo: No te lances a meter capas. Empieza entrenando con pocos datos y pocas capas. Mantén siempre un conjunto de datos de entrenamiento y uno de test. Nunca entrenes con los datos de test. Pero durante el entrenamiento ve evaluando el error en ambos conjuntos. Si ves que ambos van bajando, genial. Si el error de test empieza a diverger, necesitas más datos. Si el error de entrenamiento se estanca y lo quieres más bajo, necesitas más capas.
Espero que te ayude. Suerte!
Hola Ruben, demasiado bueno el artículo. Se agradece información de esta área en español.
Quería aprovechar de consultar, estoy buscando información (ojalá en español) sobre Deep Coding Network. La verdad todavía no me queda claro este tipo de arquitectura.
De antemano muchas gracias,
Atte,
Cristian
Gracias Cristian.
No conozco ese tipo de redes. Veo que hay un artículo del 2009 buscando el término en Google, pero es bastante denso. Me he quedado en la introducción, pero parece que sirven para aprender a la vez de datos etiquetados y sin etiquetar? Si es así, la idea es muy parecida a los auto-encoders apilados.
Si aprendes más sobre el tema y te animas a escribir algo, no dudes en compartir el enlace.
Suerte!
Buenas tardes Ruben, definitivamente felicitaciones por este gran articulo que sin duda recoge una basta información sobre el funcionamiento de deep learning como una técnica de control eficiente.
Soy estudiante y actualmente estoy desarrollando mi tesis. Necesito clasificar N movimientos a partir de 8 señales mioeléctricas, cada movimiento va a tener un valor «especifico» de señales mioeléctricas. Me han recomendado utilizar lenguaje C para utilizar SVM, pero ahora que veo deep learning me parece una técnica mas factible y mas utilizada actualmente por lo tanto los recursos serán mayores. ¿Quisiera saber con cual de las dos técnicas crees que puedo tener mas velocidad y precisión, o es independiente de la capacidad de procesamiento del microprocesador que utilice?.
De antemano gracias, y espero poder seguir en contacto.
Hola David,
Gracias por tu comentario!
Puedes utilizar SVM en múltiples lenguajes. Yo por ejemplo lo he utilizado con Python y no he tenido ningún problema.
SVM tiende a ser más eficiente en problemas simples, porque necesita ajustar muchos menos parámetros. En concreto, SVM entrena muy rápido, mientras que cualquier técnica de deep learning tarda mucho en entrenar. A la hora de evaluar, también suele ser más rápido, aunque la diferencia es menor.
La gran dificultad de SVM es diseñar un buen kernel, y en eso no te puedo ayudar, porque no tengo ninguna experiencia. En ese sentido, deep learning tiene ventaja, porque encuentra las características importantes en los datos «él solo», si tienes suficientes datos.
Si consultas los rankings de distintos algoritmos de machine learning, verás que en los problemas más difíciles, deep learning gana a SVM en precisión. Por ejemplo, en detección de dígitos escritos a mano, deep learning consigue el doble de precisión que SVM:
http://rodrigob.github.io/are_we_there_yet/build/classification_datasets_results.html
Teniendo en cuenta que hablamos de un problema de clasificación con sólo 8 señales de entrada , yo te recomendaría empezar con SVM, y sólo si ves que no consigues suficiente precisión, pasar a deep learning. Más que nada por moverte algo más rápido. Si estás haciendo una tesis, vas a necesitar hacer muchísimas pruebas, tanto de entrenamiento como de evaluación, y la diferencia de velocidad al entrenar es muy grande.
Por cierto, pregúntate si es suficiente con 8 valores instantáneos para determinar tu acción, o necesitas también los valores anteriores. Por ejemplo, si la velocidad a la que cambian esas señales es importante (la primera derivada), o incluso la segunda derivada. A lo mejor resulta que eso tampoco es suficiente y tienes que prestar atención a patrones de señales en el tiempo. Entonces ya no hablamos de 8 entradas, sino de 8 x M, siendo M el buffer de entradas pasadas que quieres tener en cuenta. Si la secuencia es importante, y no sólo el valor instantáneo, hay otro tipo de redes de neuronas que puedes utilizar: las redes recurrentes (busca LSTM). Esas redes tienen algo de memoria y se encargan ellas solas de recordar los valores anteriores y detectar patrones en el tiempo.
Mucha suerte! No dudes en comentar tus avances, tengo curiosidad…
Ruben gracias por tu aporte. La información que me has proporcionado me a servido mucho para complementar el estado del arte del proyecto y postular trabajas futuros. Por lo pronto te cuento que los objetivos de la tesis han cambiado, ahora lo primero es realizar la instrumentación de una prótesis mecánica. Luego de tener el prototipo completo pensaremos en la técnica de maquinas de aprendizaje mas adecuada para ese prototipo. Reitero las gracias por el aporte de conocimiento proporcionado y seguiremos en contacto.
Ruben buenas noches una pregunta MLP es una tecnica de deep learning? Es decir si yo creo una red neuronal con 2 o 3 capas ocultas ya estoy trabajando con deep learning?
MLP se usa un montón en deep learning. Sin embargo se suele considerar deep learning cuando tienes un número de capas mayor, y tienes que empezar a probar diferentes técnicas para que las primeras capas también entrenen.
No creo que haya un número mágico a partir del cual ya puedes llamarlo deep learning, pero si puedes entrenar tu red MLP con los algoritmos de toda la vida en un PC normalito, yo no lo llamaría deep learning.
Pero ya habrás notado que ahora que el término se ha puesto de moda, cualquiera que use una red de neuronas de cualquier profundidad ya dice que está haciendo deep learning 🙂
Pingback: ¿Deep Learning? ¿Qué es y porqué está de moda?
Pingback: Cómo crear bots conversacionales | Rubén López
Muy interesante, y fabuloso que este en Español!
Regina Castañeda
Mexico
Gracias Regina!
Pingback: Deep Learning: una rama clave en el futuro de la Inteligencia Artificial | Consultec
Hola Ruben. Mi nombre en Minia Manteiga y soy astrofisica y profesora en la UdC. Me ha gustado mucho tu articulo, se entiende muy bien. Tengo que dar una charla en un congreso sobre Big Data en Astronomía y quisiera pedirte permiso para usar algunos de tus ejemplos e imágenes, mencionando la fuente, claro.
Muchas gracias y un abrazo
Minia
Gracias Minia,
Que coincidencia, yo estudié en la UdC! Por supuesto que tienes mi permiso. Ojalá todo el mundo preguntase como has hecho tú 😉
Hola Ruben,
Primero muchas gracias por la información, me sumo a los comentarios de la mayoría, afirmando que logras hacer muy comprensible algo que es bastante más complejo.
Quería comentarte que estoy trabajando con pronósticos en series de tiempo para mi tesis y la idea es mejorar los modelos econométricos con IA.
Ya he utilzado ANN clásicas (perceptron) y me gustaría que me orientes respecto a alguna técnica más avanzada que pueda mejorar los pronósticos, por ahora solo conozco las LSTM, me gustaría mucho incluir alguna técnica o metodología de deep learning para realizar pronósticos.
Quedo atento a tus comentarios, saludos.